| <<Elöző fejezet | Tartalom | Következő fejezet>> |
1. Bevezetés
1.1. Adatbázis fogalma
1.2. Történelmi áttekintés
1.3. Adatbáziskezelők szerepe, célja
1.4. Különböző adatbázis modellek
1.4.1. Hierarchikus adatbázis modell
1.4.2. Hálós adatbázis modell
1.4.3. Relációs adatbázis modell
1.4.4. Objektum-relációs adatbázis modell
Az adatbázis rendszerek tantárgy keretén belül az adatbázis tervezés elméletét, a relációs algebra alapjait, illetve a relációs adatbáziskezelők lekérdező nyelvét (SQL) és az adatbáziskezelő működését, funkcióit és használatát (a teljesség igénye nélkül) ismertetjük. A könnyebb megértést számos gyakorlati példákkal igyekszünk megkönnyíteni.
Adatbázison köznapi értelemben adatok valamely célszerűen rendezett, valamilyen szisztéma szerinti tárolását értjük. Az adatok melyek nem feltétlenül számítógépen kerülnek tárolásra, gondoljunk csak a korábban használt könyvtári kartoték rendszerekre. Az adatbázis esetén nem az adatok nagy számán van a hangsúly, hanem a célszerű rendezettségen. Képzeljük el, hogy egy céghez naponta átlagban 20 levél érkezik. A cég irattárosa kellő adattárolási tapasztalat híján a leveleket az irattár ajtajára vágott lyukon keresztül bedobja. Elképzelhető, hogy pár év eltelte után milyen reménytelen vállalkozás egy levelet megtalálni az irattárban. Ez az adathalmaz nem tekinthető adatbázisnak, ahhoz hogy adatbázis legyen nem elegendő a nagyszámú adat. Az adathalmaz csak akkor válik adatbázissá, ha az valamilyen rend szerint épül fel, mely lehetővé teszi az adatok értelmes kezelését. Természetesen ugyanazon adathalmazból többféle rendszerezés alapján alakíthatunk ki adatbázist. Például egy könyvtárban a könyveket rendezhetnénk a könyvek mérete vagy akár a szerző vagy szerzők testsúlya alapján. Ez már egy rendszert ad az adatok tárolásához. Íly módon minden könyv helye meghatározott. De bizonyára nehéz helyzetben lennénk, ha szerző és cím alapján próbálnánk meg előkeresni egy könyvet. Az adatok tárolásába bevitt rendszernek alkalmasnak kell lennie a leggyakrabban előforduló igények hatékony kielégítésére. Az adatbázisok mellé egy adatbáziskezelő rendszer (DBMS) is járul, mely az adatbázis vagy adatbázisok üzemeltetését biztosítja. Hagyományos adatbázis esetén ez a kezelő személyzet intelligenciájának része, elektronikus adatbázisok esetén pedig valamilyen szoftver.
A számítógépes adatbázisok esetén egy egységnek tekintjük az adatbázisban tárolt adatokat és az azok visszakeresését, aktualizálását, kezelését biztosító szotfvert, ez az adatbázis-kezelő rendszer (DBMS).
Azóta rendelkezünk adatbázisokkal, mióta írásban vagyunk képesek rögzíteni adatokat. Ez az ókorban történhetett akár kőtáblákra vagy papirusz tekercsekre. Az adatbázisok fejlettebb formái később a kartoték rendszerek lettek, melyek a számítógépek megjelenéséig az alapvető adatbázis rendszerek voltak. A számítástechnika hőskorában az 50-es 60-as években az adatok tárolása még lyukszalagon, lyukkártyán történt, az adatok közvetlenül nem voltak elérhetők a számítógép számára. A mágneses háttértárolók elterjedésével az adatok tárolása egyszerűbbé, elérésük hatékonyabbá vált. Ezekben az időkben még nem léteztek univerzális módszerek illetve rendszerek, melyek segítségével az adatbázisokkal kapcsolatos problémák nagy része általánosan megoldható lett volna.
A számítógépek fejlődésével együtt fejlődtek a programozói lehetőségek is. Az első számítógépeken csak a gépi kód (a bináris formában kiadott utasítások a mikroprocesszornak) állt rendelkezésre. Ezt első generációs programnyelvnek nevezzük. Ezt követték a második generációs (assembler) nyelvek, melyekben a gépi kód helyett úgynevezett mnemonikok és szimbólumok alkalmazhatók. Az első illetve második generációs programnyelvekben még nem készültek komoly adatbáziskezelő alkalmazások. Ezekre egyrészt a magas szintű nyelvek (3. generációs program nyelvek) COBOL, FORTRAN stb., másrészről a lemezes operációs rendszerek kialakulásáig kellett várni. Ekkor már komoly adatbázis alkalmazások születtek, melyek egyedi problémák megoldására voltak alkalmasak.
Az adatbázisok méretének és számának gyors növekedése következtében az egyedi alkalmazások létrehozása fárasztó és időrabló feladattá vált, ezért a programfejlesztők törekedtek az adatbáziskezelés általános formában történő megfogalmazására. Ennek eredményeként jöttek létre az adatbázis kezelő rendszerek (DBMS) és a negyedik generációs nyelvek (4GL). Az adatbázis kezelő rendszerek számos eszközt nyújtanak az interaktív adatbevitel, menük létrehozása terén, melyek kialakítása a harmadik generációs nyelvekben sok sok oldal kód leírásával lenne csak lehetséges. A szabványos eszközök bevezetésével nem csak a programozói munka csökkent le, hanem az egységes felhasználói felület kialakítására késztetik a programozókat.
Az objektum orientált programozási nyelvek térhódításával az adatbázis kezelő rendszerekkel kapcsolatos kutatások is az objektum orientált megközelítés irányába nyitott. A kereskedelmi forgalomban kapható adatbázis kezelők azonban még nem az objektumorientált megközelítésre épülnek.
| 1. generációs nyelvek | Gépi kódú programozás |
8C C0 8E D8 |
|
| 2. generációs nyelvek | Assembler nyelvek |
MOV AX,ES MOV DS,AX |
|
| 3. generációs nyelvek | Imperatív nyelvek: Algol (1960), FORTRAN (1954), C (1973), Pascal (1970), Basic (1964) |
var i, s:integer; s := 0; for i:=1 to 10 do s := s + i; |
|
| 4. generációs nyelvek | SQL (1970), PL/SQL (1991), PL/pgSQL, MATLAB (1984) |
CREATE OR REPLACE TRIGGER my_table_before
before INSERT OR UPDATE OR DELETE ON my_table
FOR each row
|
|
| 5. generációs nyelvek | Logikai programozási nyelvek: Prolog (1970), Lisp (1960) |
(+ (cadr p1) (cadr p2) (/ 750 2)) | |
| Objektum orientált nyelvek | SmallTalk (1972), C++ (1981), Java (1994), Visual Basic |
class Complex {
protected:
double real, img;
public:
Complex();
~Complex();
Complex& operator+(Complex& a);
}
|
|
| Script nyelvek | Perl (1987), Python (1991), PHP (1995), JavaScript (1995) |
$query_str = "select $col from $table order by id";
$result = mokka_query($query_str);
while ($row = mokka_fetch_array($result)) {
$values[] = substr($row[$col], 0, $max);
}
return $values;
|
1.3. Adatbáziskezelők szerepe, célja
Manapság nem elégszünk meg egy adatbázissal, mely az adatokat rendszerezve tárolja, hanem az adatok kezeléséhez szükséges eszközöket is az adatbázis mellé képzeljük. Az így kialakult program rendszert adatbázis kezelő rendszernek (DBMS Database Management System) nevezzük. Egy DBMS egyszerűbb és gyorsabb megoldást kínál az űrlapokon alapuló alkalmazások kidolgozásában, az adatbázis adatokon alapuló jelentések készítésében. A DBMS-ek megváltoztatták a végfelhasználók adatnyerési lehetőségeit az egyszerű lekérdezési nyelvek bevezetésével. A lekérdező nyelvek lehetőséget nyújtanak a nem számítógépes szakemberek számára is tetszőleges lekérdezés gyors végrehajtására. A programozási eszközök mellett az operációs rendszerek illetve azoknak a háttértárakat kezelő része is komoly fejlődésen ment keresztül. Nem volt már szükség a fizikai fájlszerkezet pontos ismeretére, ezt az operációs rendszer illetve az adatbáziskezelő rendszer elfedte a felhasználó és a programozó elől is. Ma már az operációs rendszerek is lehetőséget nyújtanak szekvenciális, indexelt és közvetlen elérésű adatállományok létrehozására. (Ez nem igaz a PC DOS és UNIX operációs rendszerekre.) Az operációs rendszerek fájl kezelői azonban nem értelmezik a fájlok tartalmát, a fájlokat kezelő programoknak kell ismernie az adatok szerkezetét és az adatszerkezetben bekövetkezett változás, akár csak bővülés, esetén a változást a programokon is át kell vezetni. Az adatbázisokban gyakran előfordulnak olyan típusú adatok, melyeket az operációs rendszer vagy a harmadik generációs programnyelvek közvetlenül nem kezelnek, például dátum, időpont, pénzegység stb.
Az adatbáziskezelők az operációs rendszerekhez hasonlóan számos eszközt szolgáltatnak a gyakran előforduló problémák megoldására, de míg az operációs rendszerek a perifériák kezelésére és a fájlok használatára adnak lehetőséget, addig a DBMS-ek eszközei egy magasabb szintű absztrakcióra épülve az adatok logikai szintű elérését támogatják a rekordokon belüli bájt poziciók helyett, továbbá eszközöket tartalmaznak az adatok űrlap szintű kezelésére illetve jelentések és menük készítésére.
Az adatbáziskezelők három alapvető feladat körre alapozódnak, melyek mindegyike a számítógépes hardvertől és környezettől való függetlenséggel kapcsolatos. Az általános cél az, hogy inkább az ember gondolkodásához, munkastílusához hozza közelebb az információs rendszer kidolgozását, minthogy az embereket kényszerítse a számítógép stílusú gondolkozásra.
Az adatbáziskezelőket használva nagyobb hatékonyság érthető el az alkalmazások fejlesztésében. Így ugyanaz a feladat kisebb fejlesztőcsoporttal vagy rövidebb idő alatt oldható meg.
A korszerű adatbázis-kezelő rendszerek az adatok mellett az adatokra vonatkozó konzisztencia szabályokat illetve az egyes felhasználók jogosultságait is tárolják. Az adatok elérése csak az adatbázis-kezelő rendszeren keresztűl, szabványos nyelvet használva (SQL), a konzisztencia és jogosultsági szabályok figyelembevételével történhet meg. Biztosítják a felhasználóknak az adatok konkurens elérését és az ebből adódó konfliktusok kezelését.
1.4. Különböző adatbázis modellek
Az adatbáziskezelők fejlődése során többfajta logikai modell alakult ki, melyek főként az adatok közötti kapcsolatok tárolásában térnek el egymástól. Ilyenek, a teljesség igénye nélkül, a hierarchikus, a háló, a relációs, az objektum relációs és az objektum orientált modell. Ezek közül manapság a Windows illetve UNIX operációs rendszerekben döntően a relációs modellre épülő adatbáziskezelőket használnak. Ezért itt csak röviden ismertetjük a többi modellt.
1.4.1. Hierarchikus adatbázis modell
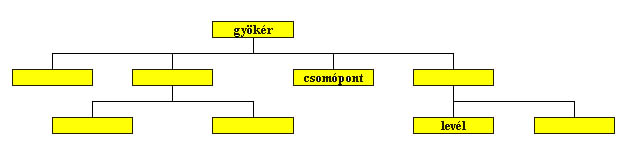
A hierarchikus modell volt a legelső az adatbáziskezelőkben és egyben a leginkább korlátozott. A hierarchikus modell az 1960-s évek végén alakult ki és az 1970.s évek végéig használták. Például az IBM IMS adatbáziskezelő rendszer alkalmazta ezt a modellt. A neve is utal rá, hogy az adatokat egy hierarchiában kell elrendezni. Ezt egy fa szerkezettel tehetjük szemléletessé.
1.1 ábra Hierarchikus adatmodell
Az adatbázis több egymástól független fából állhat. A fa csomópontjaiban és leveleiben helyezkednek el az adatok. A közöttük levő kapcsolat, szülő gyermek kapcsolatnak felel meg. Így csak 1:n típusú kapcsolatok képezhetők le segítségével. Az 1:n kapcsolat azt jelenti, hogy az adatszerkezet egyik típusú adata a hierarchiában alatta elhelyezkedő egy vagy több más adattal áll kapcsolatban.
A hierarchikus modell természetéből adódóan nem ábrázolhatunk benne n:m típusú kapcsolatokat (lásd a háló modellt). Emellett további hátránya, hogy az adatok elérése csak egyféle sorrendben lehetséges, a tárolt hierarchiának megfelelő sorrendben.
A hierarchikus adatmodell alkalmazására a legkézenfekvőbb példa a családfa. De a főnök-beosztott viszonyok vagy egy iskola szerkezete is leírható ebben a modellben. Az iskola esetén többféle hierarchia is felépíthető. Egyrészt az iskola több osztályra bomlik és az osztályok tanulókból állnak. Másrészt az iskolát az igazgató vezeti, a többi tanár az ő beosztottja és a tanárok egy vagy több tantárgyat tanítanak.
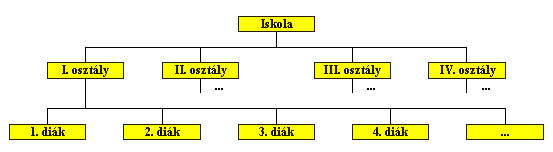
1.2 ábra Iskola hierarchikus felépítése a diákok szemszögéből
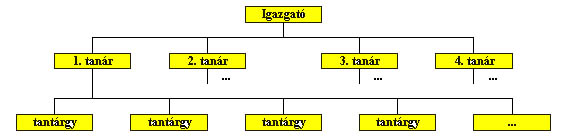
1.3 ábra Iskola hierarchikus felépítése a tanárok szemszögéből
A hálós adatmodell esetén az egyes azonos vagy különböző összetételű adategységek (rekordok) között a kapcsolat egy gráffal írható le. A gráf csomópontok és ezeket összekötő élek rendszere, melyben tetszőleges két csomópont között akkor van adatkapcsolat, ha őket él köti össze egymással. Egy csomópontból tetszőleges számú él indulhat ki, de egy él csak két csomópontot köthet össze. Azaz minden adategység tetszőleges más adategységekkel lehet kapcsolatban. ebben a modellben n:m típusú adatkapcsolatok is leírhatók az 1:n típusúak mellett. 1971-ben az adatrendszer nyelvek konferenciáján (CODASYL) definiálták.
A hierarchikus és a hálós modell esetén az adatbázisba fixen beépített kapcsolatok következtében csak a tárolt kapcsolatok segítségével bejárható adat-visszakeresések oldhatók meg hatékonyan (sok esetben hatékonyabban mint más modellekben). További hátrányuk, hogy szerkezetük merev, módosításuk nehézkes.
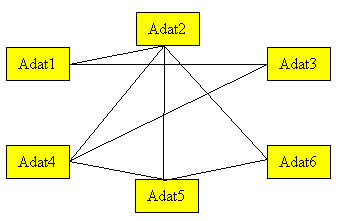
1.4 ábra Hálós adatmodell
Az iskolai példánál maradva az egyes diákok illetve tanárok közötti kapcsolat hálós modellben írható le. Minden diákot több tanár tanít és minden tanár több diákot tanít.
1.4.3. Relációs adatbázis modell
A relációs az egyik legáttekinhetőbb és a 80-as évektől kezdve a legelterjedtebb adatmodell. Kidolgozása E. F. Codd (1923-2003) nevéhez fűződik, 1970-ben jelent meg alapvető műve a ""A Relational Model Data Large Shared Data Banks". A relációs modellben az adatokat táblázatok soraiban képezzük le. A legfontosabb eltérés az előzőekben bemutatott két modellhez képest az, hogy itt nincsenek előre definiált kapcsolatok az egyes adategységek között, hanem a kapcsolatok létrehozásához szükséges adatokat tároljuk többszörösen. Ezzel egy sokkal rugalmasabb és általánosabb szerkezetet kapunk. A relációs modellt részletesen tárgyaljuk a következőkben.
1.4.4. Objektum-relációs adatbázis modell
Az objektum relációs adatmodell a relációs adatmodell bővítésével állt elő. Egyrészt az objektum orientált megközelítésben használt osztály, objektum, öröklődés fogalmakat alkalmazza az relációs adatbázis táblákra és a lekérdező nyelvet is ez irányba bővíti. Másrészt pedig támogatja az adatmodell bővítését saját adattípusokkal és azokat kezelő beépített függvényekkel. Az objektum relációs modellel is bővebben foglalkozunk a későbbiekben.
| <<Elöző fejezet | Tartalom | Következő fejezet>> |