Az adatbázis szervezés szintjei
Az adatbázisban a valós világ adatait, és azok egymáshoz való kapcsolódását
kívánjuk tárolni. Ahhoz azonban, hogy a valóban tárolandó adatokat és a
szükséges kapcsolatokat megállapíthassuk, valamint, hogy ezeket az adatokat a
számítógép számára érthető formában tárolni tudjuk, az általánosításnak egy
magas szintjére van szükség. Ezt az absztrakciós folyamatot más szóval modellezést,
célszerűségi okokból, több lépcsőben szokás végrehajtani.
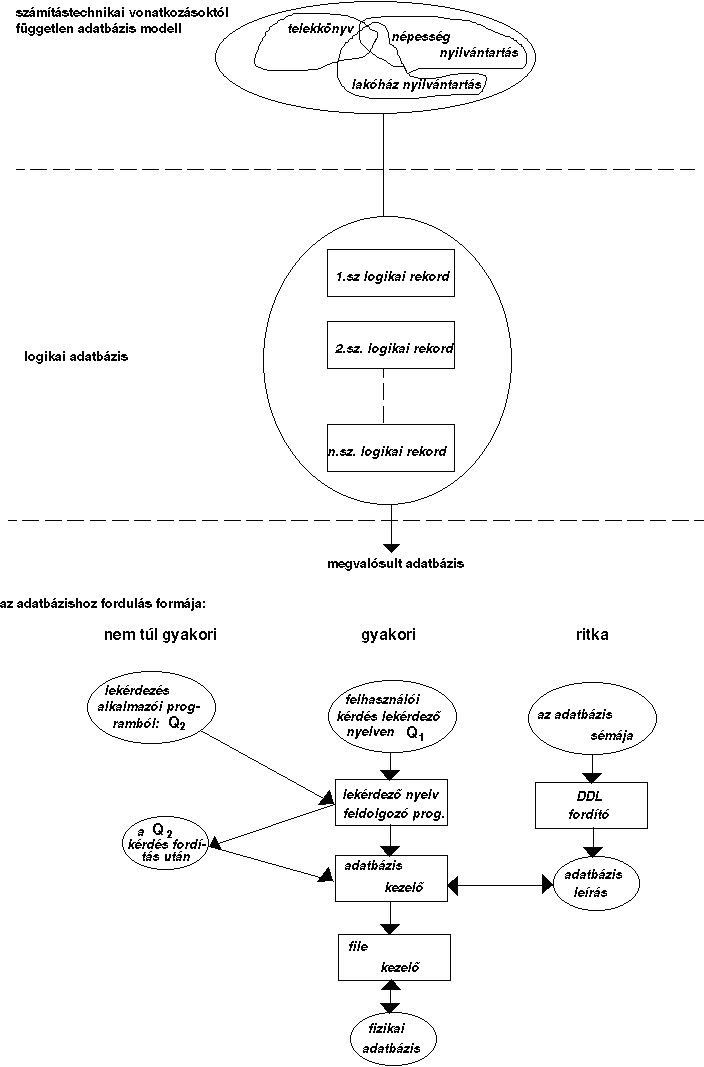
1.3 ábra - a modellezési folyamat
főbb állomásai
Az első feladat az adatmodellezés. Ez a feladat még nem igényel
számítógépes ismereteket és lényegében független az alkalmazandó szoftvertől.
Ugyanakkor a feladatot csak olyan emberek oldhatják meg eredményesen, akik mind
átfogóan, mind részleteiben is jól ismerik a földolgozandó területet. Ha
például egy városigazgatási alfanumerikus adatbázist akarunk létrehozni, akkor
mindenekelőtt föl kell tárnunk azt, hogy az igazgatási szervezet különböző
feladataihoz milyen nyilvántartásokat használ hagyományos munkamód esetén.
Ezután meg kell néznünk azt, hogy melyek a közös adatok az egyes
nyilvántartások között, valamint azt is, hogy különböző feladatok megoldására
milyen további kapcsolatokat volna célszerű kialakítani. A föltárt
összefüggéseket úgynevezett entitás diagramokban grafikusan is
ábrázolni tudjuk.
E diagramok alapján kerülhet sor a második lépcsőre, az adatbázis
logikai szerkezetének kialakítására. E logikai rekordoknak egyrészt
összhangban kell lenniük az adatmodellezés során föltárt jelenségekkel,
másrészt ki kell elégíteniük az adatbázis adatleíró nyelve (Data
Definition Language) által megszabott formai igényeket.
A harmadik lépésben ezeket a logikai rekordokat a DDL szabályai
szerint deklaráljuk, s ilyen módon megteremtjük a lehetőségét az adatbázis
tényleges adatokkal való föltöltésének. A DDL nyelv segítségével ugyanis
csak a rekord neveket, formátumokat és kapcsolataikat rögzítettük, a tényleges
adatokat majd a betöltési folyamatban kell az így kialakított keretbe
elhelyezni. A DDL nyelven leírt adatbázis sémát a DDL compailer
lefordítja, és létrehozza az adatbázis leírását (sémáját). Ezt
a leírást felhasználva fogja az adatbázis kezelő (data base manager)
a file kezelő (file manager) segítségével elhelyezni fizikai tároló
helyükre a bevitt adatokat. Itt szeretnénk megjegyezni, hogy a nagy
adatbázisokban az adatbázis sémája mellett még úgynevezett alsémák is
deklarálásra kerülnek, a különböző felhasználói szempontok figyelembevételével.
Mivel azonban mi az alfanumerikus adatbázisokat csak a térbeli információs
rendszerekben betöltött szerepük szempontjából vizsgáljuk, ezért az egyszerűség
kedvéért úgy tekinthetjük, hogy az általunk használt adatbázisok nem bomlanak
további alsémákra.
Az adatbázisokhoz való hozzáférés két szinten történhet. Vannak olyan
felhasználók, akik számítógépes ismeretek nélkül is a döntés előkészítés
folyamatában adatokat kívánnak szerezni az adatbázisból. Ezek a felhasználók
rendszerint az alkalmazói programok bemenetén jutnak az adatbázisba. Ezek az
alkalmazói programok ugyanis úgy vannak kialakítva, hogy néhány rövid parancs
bebillentyűzése után megadják a kívánt választ. A számítógép szempontjából a
válaszadás úgy történik, hogy a kérdés bebillentyűzése után a lekérdező
processzor beindítja a lefordított felhasználói programot, mely az adatbázis
manager segítségével megszerzi a kívánt adatokat. Sokkal gyakoribb a lekérdező
(query) nyelven keresztüli hozzáférés. A korszerű adatbázisok lekérdező
nyelvei utasítások és paraméterek segítségével lehetővé teszik azt, hogy az
adatbázisban tárolt adatok különböző feldolgozási formában elérhetővé váljanak.
E bemeneten keresztül rendszerint gyakorlott operátorok veszik igénybe a
rendszert. A lekérdező nyelv utasításait a lekérdező processzor
közvetlenül az adatbázis managernek továbbítja, és ez szolgáltatja a
kívánt információt.
Amint arról már szoltunk, az adatbázisban különválik a logikai és
fizikai rekordszerkezet. Ezt a különválasztást az adatbázis manager
végzi. Különböző logikai rekordokból általános esetben különböző fizikai
rekordokat hoz létre és ezeket a fizikai rekordokat az operációs rendszer
részét képező file manager a meglévő tárakban az általa kijelölt
helyekre elhelyezi. Ez utóbbi témáról, azaz a fizikai tárolás módjairól a
továbbiakban nem kívánunk szólni, hisz minden operációs rendszer ezt a
feladatot a saját szabályai szerint látja el. Számunkra, felhasználók számára éppen
az a lényeges a korszerű adatbázis koncepcióban, hogy nem kell foglalkoznunk a
fizikai adatszervezés kérdéseivel.
·
a következő rész az elemi
adatszerkezetekkel foglalkozik,
·
visszatérhet az előző részhez is,
·
vagy a tartalomjegyzékhez.
Megjegyzéseit E-mail-en várja a
szerző: Dr Sárközy Ferenc